函数级别的代码改动关联影响分析工具
2022-04-14
TL;DR
本文记录了最近实现的前端代码改动关联分析工具的实现思路。该工具可以识别你的代码改动,从函数级别的颗粒度找到代码改动对其他函数或页面的影响,并输出影响报告,从而提高开发人员的测试效率和测试范围。可以在 GitHub 上查看其代码。
背景
由于长期的业务迭代,业务代码规模越来越大,改动引发现象频发。我们修改一块老代码时,不是很清楚它是否会对其他模块产生影响。这时候许多人的做法是单纯测一下这个页面(功能),没问题就行了,提测下班;或者使用编辑器的搜索功能全局搜索一下某些关键信息,看这个修改的东西在哪里用到了,附带看一下有没有影响。
如果当前修改的内容是独立的,或者用的地方不多,那么简单的测试往往也不会造成质量问题,但这种检查方式本身也不算高效,我们往往需要在代码文件里跳来跳去。因此如果有个工具,它可以识别你的修改,自动的给你找出你这个修改影响了哪些地方,是不是可以节省很多时间同时也提高自测质量呢?
思路
我们的目的是根据代码的修改找到最终的影响面,这里有个很重要的词——「找」。拿什么找?找什么?
拿什么找?
拿什么找?拿代码的修改找。不过这个修改是零零碎碎的,我们是要追踪一个「数据变量」的变化导致的影响?我们是要追踪一个「函数变更」的影响?因此在做这个分析之前,我们需要先确定「颗粒度」。
如果是以「数据变量」为颗粒度,这个颗粒度非常细,而且对于 JavaScript 这种静态语言来说,在纯代码文本层面要做数据变量的追踪是非常困难的。因此选择「函数」作为颗粒度是比较合适的,毕竟业务功能也是由一个一个的函数组合完成的。
所以拿「函数」去找,也就是说颗粒度为函数级别。
找什么?
我们最终的目的是为了更好的测试,那么我作为一个前端开发人员,我关注的是:
- 我这个函数被哪些函数调用
- 我这个函数或者函数调用链上的函数被用在页面上的哪个地方,即对页面功能有什么影响
所以要找「调用链」和「页面影响」。
如何实现
从目的出发,可以拆解出如下几件要做的事情:
- 因为要知道当前哪些函数发生了变更,即影响因子,所以需要根据当前代码的修改(文件的变化)得出函数变化
- 因为要得到函数的调用链,所以要构建整个项目的函数调用关系
- 因为要知道函数变更对页面的影响,所以要提取页面上 html 中的变量使用
- 将影响因子作为输入,在函数调用关系和页面数据中找到影响面并输出
整体流程如下图所示:
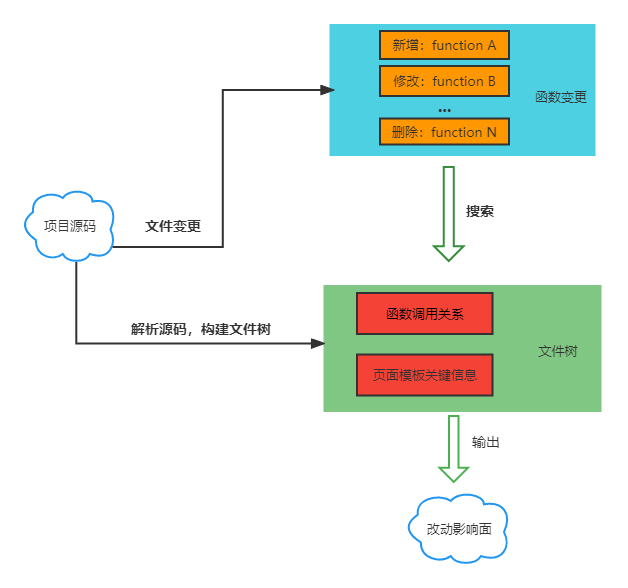
该工具当前只关注 JavaScript 和 Vue 技术栈的项目,所以后文都是针对这俩技术栈的情况来做的。
文件变化得到函数变化
获得函数变化情况
只需要对修改前后的文件内容进行对比,就可以从文件变化中获得函数变化情况。比如之前文件中有某个函数,现在没了,那就说明这个函数被删除了;如果现在和之前都有,但是函数体内容变了,那就说明函数修改了。
我们将 JavaScript 代码转为抽象语法树,遍历 JavaScript AST 并收集函数节点。集合中每个函数元素的定义如下:
{
name: 'function_name',
text: 'function block content...'
}
其中 name 是函数名称,这个可以在 AST 中获取到;text 是函数体的文本内容,这个似乎是无法在 AST 中拿到的,不过可以绕一下,先通过 AST 中 loc 属性拿到函数所在的起始行,然后再从文件中读取该范围内的文本内容来获得。
所以只要对比这两个集合中的节点,就可以知道函数变化情况了。
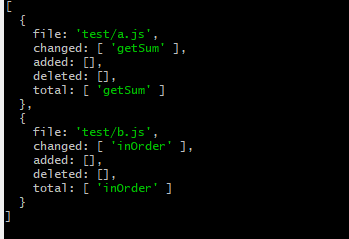
获得文件变更前的内容
但是,如何获取文件变更前的文本内容呢?当然这里要限定该项目必须已使用 git 管理。我立马想到,git 在文件恢复操作时,是怎么找到旧文件内容的?可以阅读这里了解一下。我简单概述一下。
在使用 git 管理项目时,根目录会生成 .git 文件夹,其中有个 objects 目录,我们的数据存储在该目录内以 40 位哈希值命名的文件中。
git 有三种类型的数据对象:
- 提交对象: commit object
- 树对象:tree object
- 文件对象: blob object
它们之间的关系如下
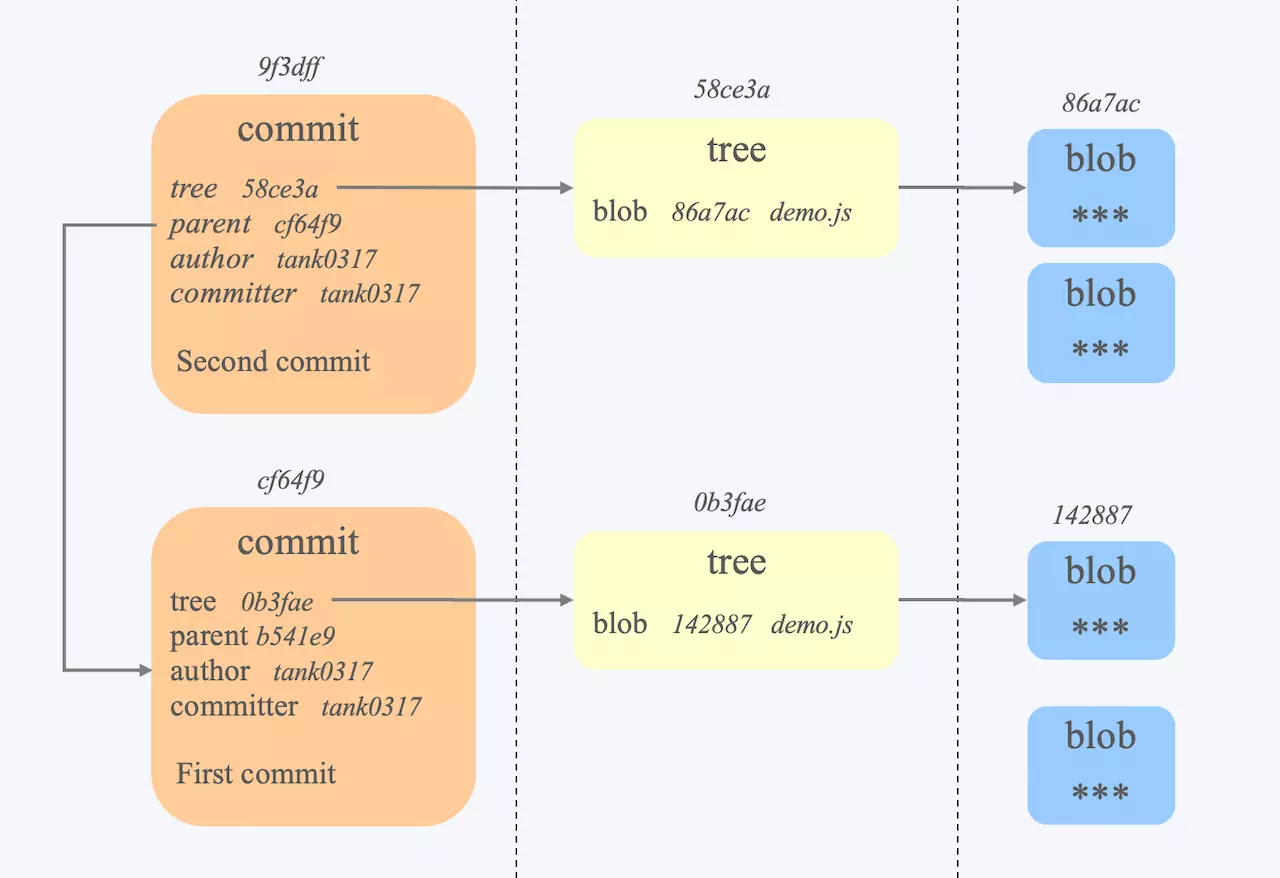
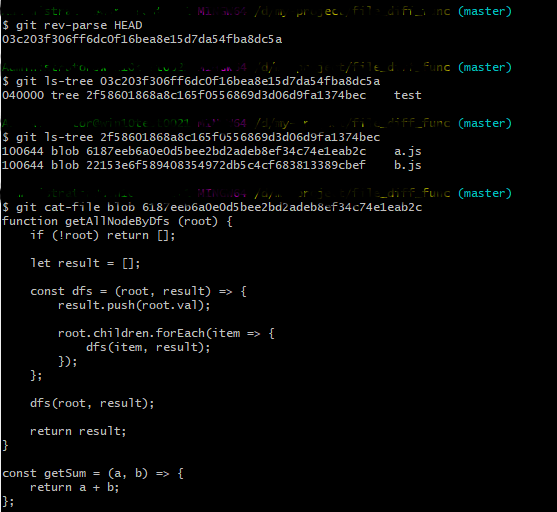
所以通过 commit id 可以获取到 tree id,通过 tree id 可以获取到 blob id,而拿到了 blob id 就可以通过 git cat-file blob <blob id> 读取到文件内容了,大家可以在自己本地实验一下。当然也不必那么麻烦,git 提供了递归命令一步到位,使用 git ls-tree -r <commit id> 就可以获得所有的 blob 信息。
获得函数调用关系
函数调用关系必然需要分析整个项目的所有文件,并将每个文件中的函数信息提取出来。
第一步:构建由所有的文件组成的「文件树」
解析所有的文件构成文件树:
{
'src/1.vue': {...},
'src/2.js': {...}
}
每个文件节点中有如下属性,具体属性的内容在后文提到:
{
file: 'src/1.vue',
allFuncsInfo: {}, // 该文件中的函数信息
importPkgs: {}, // 该文件导入的依赖
mixin: [], // 该(vue)文件中所使用的 mixin 文件
templateKeyInfo: [] // (vue)文件中模板上的关键信息
}
第二步:解析单个文件中的函数数据
即文件节点的 allFuncsInfo 属性。它的数据结构示例如下:
{
"submit": {
"name": "submit",
"filePath": "src/1.vue",
"callFnList": ["isExistRef", "$ok"] // 该函数内调用了哪些函数
},
...
}
它是 key-value 形式的数据:
- 每一个 key 是该文件中定义的函数。这个可以遍历 Javascript AST 中的函数节点拿到;
- 每一个 key 对应的 value 为一个对象,其中的主要信息为 callFnList 这个数组,该数组保存函数内部调用的其他函数。这些被调用的函数可以在 AST 的函数节点中搜索 CallExpression 节点获取,不过这里需要注意处理回调函数的场景,对于回调函数需要递归遍历。
这里需要对文件进行抽象语法树分析,因此可以在访问 AST 时访问 importDeclaration 节点,将导入的(函数等)内容确定,即文本节点中的 importPkgs 属性。
第三步:解析单文件中的 template 数据
即文件节点的 templateKeyInfo 属性。它存储的是 Vue template 中所有可能用到的变量信息。
以一个简单的 template 为例:
<template>
<div @click="handleClick">
<child-component v-if="getValue() > 1" :title="getTitle"></child-component>
</div>
</template>
我们需要将 handleClick、getValue 等数据提取出来。可以使用 vue-template-compiler 库将 template 解析为 AST,对 AST 进行深度优先遍历将 template 中的关键信息提取出来,结果如下:
{
type: 1,
tag: "div",
vBinds: [],
events: [
{
click: 'handleClick'
}
],
children: [
{
type: 1,
tag: "child-component",
vIf: 'getValue',
vBinds: [
{
title: "getTitle"
}
],
children: [...]
},
...
]
}
一般变量的使用主要在 v-if、v-bind、事件、样式绑定、“Mustache”语法上,然而不同的人有不同的代码写法,所以要从模板上非常准确的解析出变量还是有一点难度的。
第四步:处理 mixin 和确定函数来源
在对整个项目中所有的文件进行上述几步处理后,此时文件树形态如下:
// 文件树
{
'a.vue': {
file: 'a.vue',
allFuncsInfo: {
submit: {
name: 'submit',
filePath: 'a.vue',
callFnList: ['isExistRef', '$ok', 'nameValidator']
}
},
importPkgs: {
isExistRef: 'src/util.js'
globalValidators: 'src/mixin/validators.js'
},
mixin: ['globalValidators'],
templateKeyInfo: [// ....]
},
'b.vue': { ... },
'c.js': { ... }
}
以 a.vue 为例,它混入了 globalValidators ,从 importPkgs 中我们可以拿到 globalValidators 这个 mixin 的路径,因此可以在文件树中找到名为 src/mixin/validators.js 的值,将它的 allFuncsInfo 合并到 a.vue 的 allFuncsInfo 中即完成了混入。
a.vue 中定义了 submit 函数,该函数调用了其他函数。它所调用的其他函数可能来自于以下几种情况:
- 从其他文件中导入的函数:从 importPkgs 中可以拿到路径
- 在该文件中定义的其他函数:allFuncsInfo 的 key 就是该文件内的所有函数,因此可以判断出一个函数是不是定义在同文件内
- Javascript 内置函数或全局函数:来源非上面两个,这个无法找到来源,因此将来源置为 ‘un_know’
综上所述,此时我们只需要对文件树进行遍历,就可以确定文件中的所有函数来源。注意下面的 callFnFrom 字段:
// 文件树
{
'a.vue': {
file: 'a.vue',
allFuncsInfo: {
submit: {
name: 'submit',
filePath: 'a.vue',
callFnList: ['isExistRef', '$ok', 'nameValidator'],
callFnFrom: { // 新增字段
isExistRef: 'src/util.js',
$ok: 'un_know',
nameValidator: 'src/mixin/validators.js'
}
}
},
importPkgs: {
isExistRef: 'src/util.js'
globalValidators: 'src/mixin/validators.js'
},
mixin: ['globalValidators'],
templateKeyInfo: [// ....]
},
'b.vue': { ... },
'c.js': { ... }
}
那么至此,完整的文件树就构建好了。
搜索影响面
当文件树完成构建后,确定影响面就非常简单了。
假设我修改了 src/util.js 中的 isExistRef 函数,我在文件树对每个文件的 allFuncsInfo 进行遍历,如果 callFnList 中含有 isExistRef 函数,且 callFnFrom 中该函数的来源也是 src/util.js 函数,就说明找到了一处函数调用路径 submit -> isExistRef;此时继续遍历该文件的 templateKeyInfo 中的数据,如果存在 isExistRef 或 submit 函数的使用,则说明找到了一处页面影响。
如果要找到多处的、完整的调用路径,那么就要不断地对找到的函数进行上述搜索,比如继续使用 a.vue 中的 submit 函数继续搜索。因此很显然这里要进行递归操作。使用队列实现的伪代码如下:
/**
* treeData 为文件树数据
* funcInfo 是给定的搜索条件,它是一个 key-value 形式的数据,包含:name 函数名;file 函数所在文件
*/
function getImpact (treeData, funcInfo) {
let callList = [funcInfo];
while (callList.length) {
const curFuncInfo = callList.shift();
// 找到哪些函数调用了该函数
// 找到该函数影响哪些模板
const { theyCallYou, /* 其他数据 */ } = findWhoCallMe(treeData, curFuncInfo);
if (!theyCallYou.length) { // 说明这个函数没有被任何函数调用,即是调用链的尾部
// 该调用路径到头了,这里做一些收集工作
} else {
callList.push(...theyCallYou); // 存入队列中,继续遍历
}
}
}
我们在搜索过程中不断地保存函数调用路径和页面影响,最终结果就是想要的影响面,结果的一部分截取如下图所示:
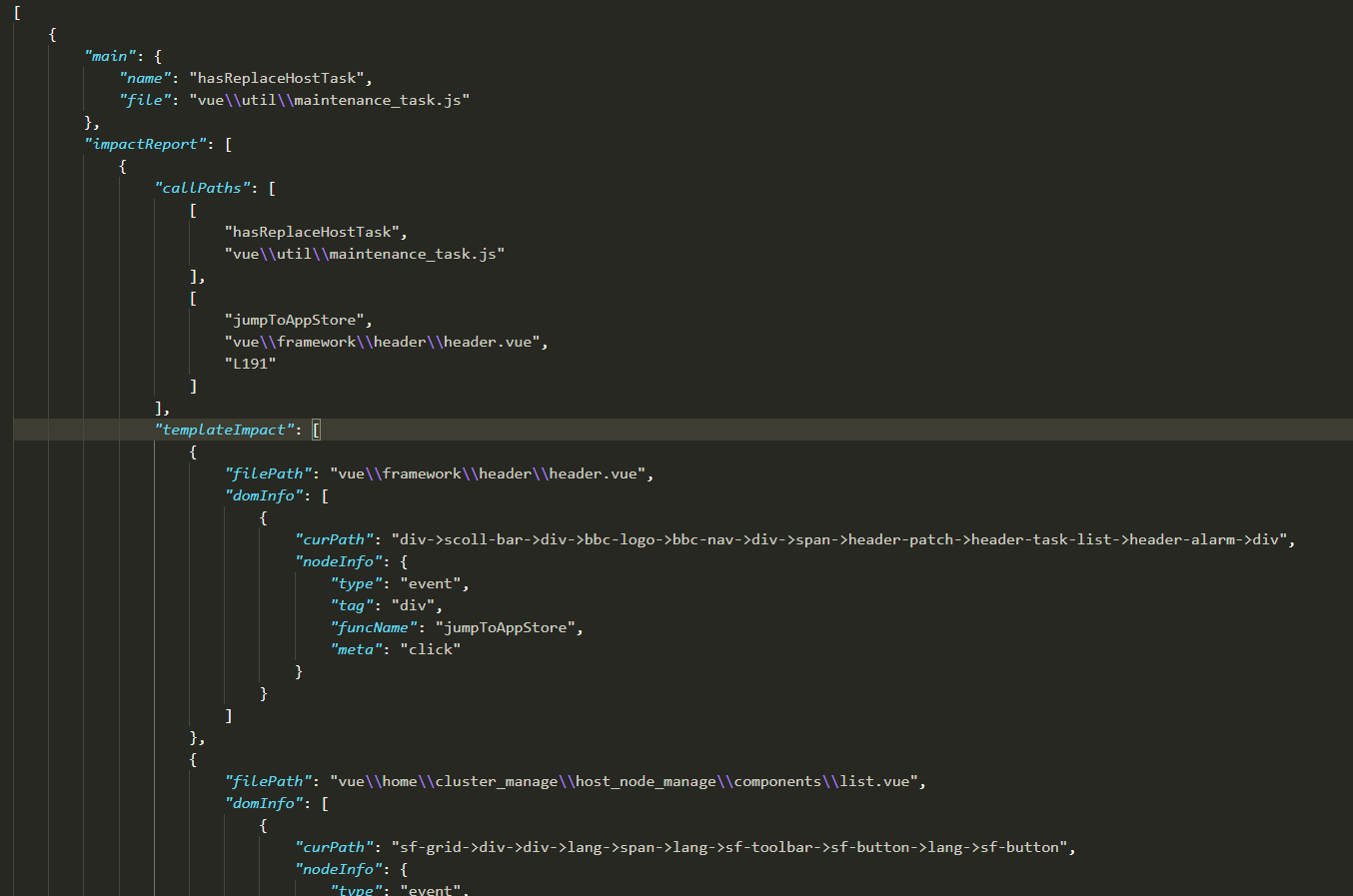
- main 字段表示影响因子,即发生变更的函数
- callPaths 字段表示调用路径,数组中每一个元素表示一个函数(包括函数所在文件、行数)。数组中的顺序实际上是被调用关系,如图中结果所示一条调用路径是
hasReplaceHostTask -> jumpToAppStore - templateImpact 字段表示模板影响。这里可以看到 dom 节点的路径和影响的具体内容。例如图中所示,该调用路径会影响
header.vue中的 click 事件
这个报告清晰的展示了本次改动的影响面,我们只需要看一下报告就知道应该测试哪些地方。
其他
上面描述了该工具实现的主要思路,在实际编码实现时有许多的细节问题,比如函数调用路径成环等。抛开细节和不同的技术栈的支持度不言,这个实现还存在一些问题。
这个实现思路的时间复杂度是比较高的,在构建文件树时要对所有文件进行多次遍历;在判断影响面时,每个函数的被调用关系判断都需要遍历整个文件树。不过从现实使用来说,判断影响面这个操作一般是在功能开发完成后进行,从频率上来说不高,因此对时间并没有特别高的要求。这些时间就起来接杯水活动一下吧!
同时当前对于函数的提取有一定的局限性。这里可以把函数调用分为「显式调用」和「隐式调用」。前者则是很清晰的 A() 或 this.A() 等调用;后者则是像继承、$refs 等。我们当前的处理很显然主要是「显示调用」。
影响面报告本身是以 json 的形式展示,在拿到这个结果后,可能依然需要去代码中看一下所在的函数或者模板内容。而有些开发人员在提测或提交代码时,可能需要编写改动的测试建议,那么针对这个场景,这份报告就有一定的局限性了,因为这个被提供测试建议的对象可能是测试人员,他并不懂代码,因此如何将影响面报告做得更语义化也是值得思考的问题。