代码改动关联分析和GitLab打通
2022-06-21
之前的 博文 介绍了 Coderfly ,近两周在它基础上做了点比较有意思的工作,将它和 GitLab 打通,打造一个易配置、无感知的工作流,我叫它为 coderfly-flow。
它的价值在于,每一次提交合并请求后,触发服务,服务会将改动关联影响结果以 Review 的形式在合并请求下评论,同时也提供更详细的报告查询。如果开发者认为自测没问题了,就关掉该问题。假设后面本次改动造成了改动引发,而回过头看到关联分析服务已提醒了该影响,那么就说明自测并不仔细。说白了是两个意义:一方面是给开发者自测建议;另一方面是提供了质量回溯的方式。效果如下:
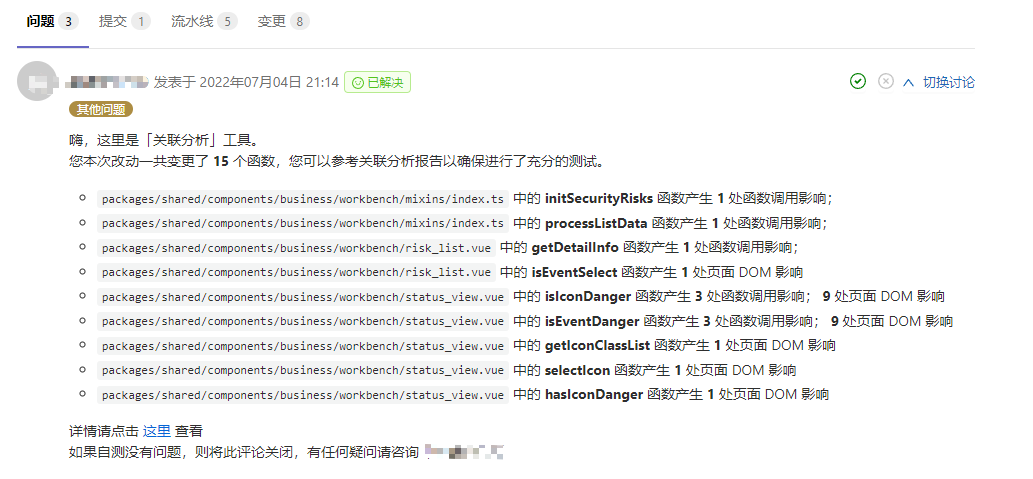
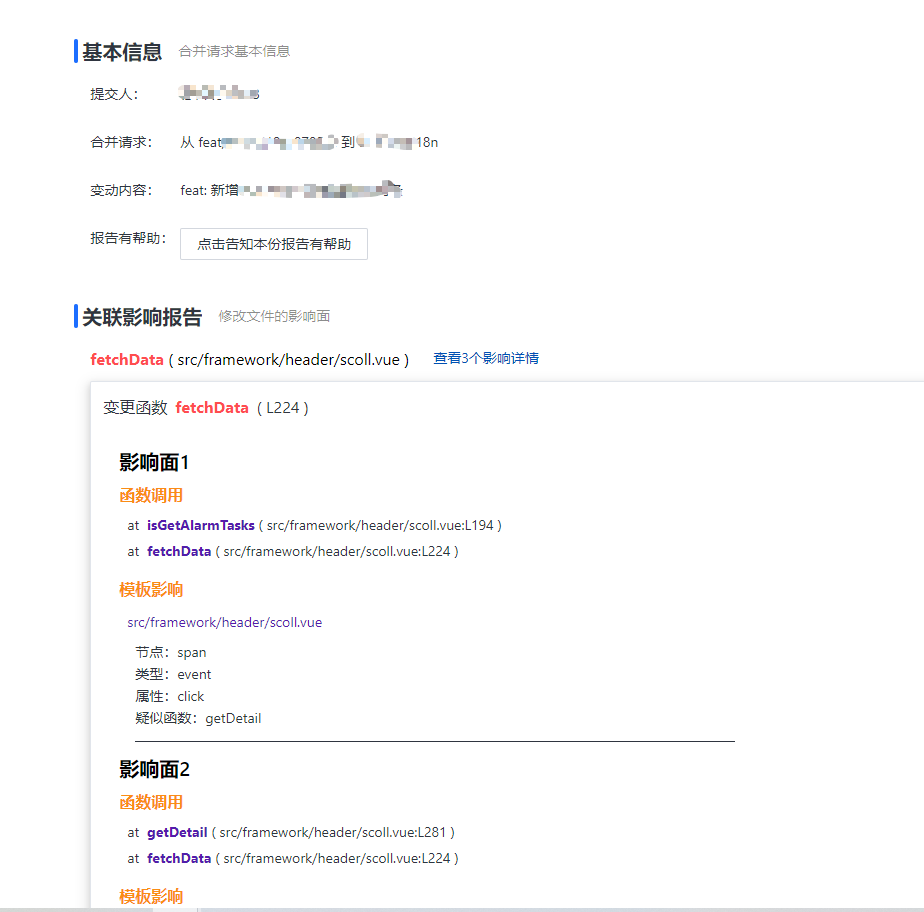
它的整个流程如下,如果看过之前的 代码质量检测工具服务端设计 便能发现二者是相似的,都是对 GitLab上的某一个提交或分支的代码进行扫描。
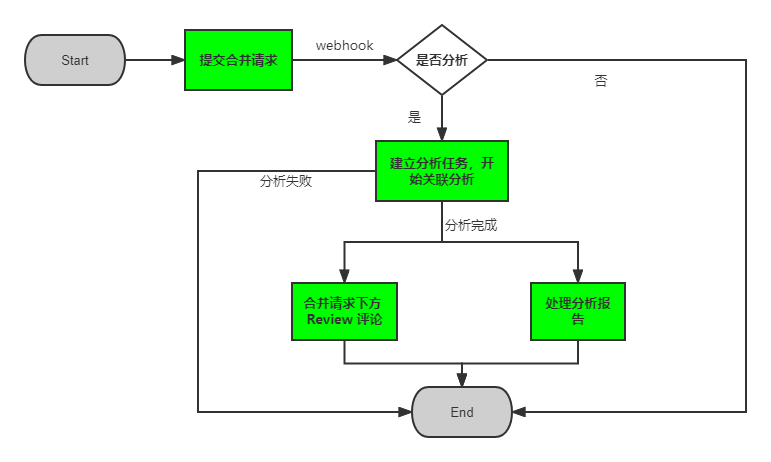
我并不认为做相似的工作是一件轻松的事情。首先,解决相似的问题往往会依赖过去经验,而过去的经验并不一定是最佳实践,最常见的例子便是过一段时间再回过头去看自己之前写过的代码,会觉得很多地方写得不好;另外,既往的经验增长的不仅是解决问题的信心,同时还有分析问题的掉以轻心,很多潜在的问题会在开始时被忽略。由于二者的技术方案大方向一致,所以本文关注的是这两件相似工作「存异」的部分。
Webhook 还是 CICD
在「代码质量检测」(bcode)中,当提交合并请求后触发流水线,流水线中预先构建好的脚本开始将此分支代码压缩上传到服务端进行扫描。我在 coderfly-flow 中故技重施,毕竟有老代码可以直接复用。一顿操作后,顺利的跑了起来,但是后面准备尝试第一个项目时,我将这一块代码全部删除了,重构为 webhook 方式。原因在二:
- 准备尝试落地的第一个项目是前后端同仓的项目,我对自己的 shell 脚本编写能力不自信,不敢保证不会影响后端大几百行的脚本
- 大家对之前 bcode 的接入方式并不喜欢,因为流水线会一定程度影响它们的合并请求
任务资源竞争
由于现在是 webhook 方式触发,那么自然服务器收不到代码了,所以必须由服务端进行代码 clone。webhook 中携带的参数是足够做这件事的,但必然不能每个合并请求都 clone 代码,有些代码好几十 G,等到代码 clone 完毕,合并请求都被合并了,分析还有啥价值。因此必须在项目接入该服务前,提供接口在服务器上提前 clone 代码。后续通过 fetch 和 checkout 命令切换到不同的分支获得对应分支的代码。那么这里就出现了一个问题,同个项目的所有合并请求分析都是在同一份代码中进行的,这些分析任务并不是有序的,因此任务之间会存在资源竞争。
对于这种问题,我有两种思路:
- 方案一:当提前 clone 源码后,对该源码打个压缩包。假设现在有 A 和 B 两个合并请求,那么就在当前文件夹下解压这个压缩包两次到 A 和 B 文件夹内,这样两个合并请求的分析工作就互不干扰了
- 方案二:这种问题一般的关键字都是「锁」。这个场景让我想到秒杀系统,于是得到了关键字「Redis 分布式锁」。
方案一个人觉得还挺巧妙的,但并不是个好方案,因为 clone 源码后的压缩、任务执行前的解压缩都是 CPU 密集型任务,资源消耗和时间消耗都非常大。我编写了代码进行了尝试,任务常常会因为挂起时间过长而失败。
因此选择使用方案二。以项目的 url 为 key 加锁,任务在加锁失败时不断去尝试获取锁,加锁成功方才执行任务,这样就可以保证一份代码下只有一个任务在操作。这个应用只会部署在一台服务器上,因此它只是简单的单实例分布式锁。
上锁
Redis 2.8 版本之后支持 set 命令传入 setnx、expire 扩展参数,避免了 setnx 非原子性操作的问题,所以直接利用 set 命令即可。
- value:设置的值
- EX seconds:设置的过期时间
- PX milliseconds:也是设置过期时间,单位不一样
- NX|XX:NX 同 setnx 效果是一样的
set key value [EX seconds] [PX milliseconds] [NX|XX]
释放锁
释放锁将 key 删除掉即可,但忘记之前在哪个博文里看到过释放锁并不能仅仅使用 del key 删除掉,这样很容易删除掉别人的锁。假如某个任务的处理时间超过了锁自动释放的时间,此时锁被其他任务占用了,那么此时释放的是别人的锁。所以这里要保证释放的只是自己的锁。因此在 del key 之前先判断这个 key 的 value 是否是指定值。方式是借助 Lua 脚本实现。
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
Node.js 单实例分布式锁完整代码
export async function lock (key: string, val: string) {
return (async function _loopLock() {
try {
const result = await redis.set(key, val, 'EX', REDIS_LOCK_SECONDS, 'NX');
// 上锁成功
if (result === 'OK') {
return true;
}
await sleep(3000);
return _loopLock();
} catch(err) {
throw new Error(err);
}
})();
}
export async function unLock(key: string, val: string) {
const script = "if redis.call('get',KEYS[1]) == ARGV[1] then" +
" return redis.call('del',KEYS[1]) " +
"else" +
" return 0 " +
"end";
try {
const result = await redis.eval(script, 1, key, val);
if (result === 1) {
return true;
}
return false;
} catch(err) {
throw new Error(err);
}
}
自动生成任务脚本
假设此时我们的待扫描的项目 A 的代码存放在 /mnt/code 下,在 bcode 中,每一个任务都是新开子进程执行,我的做法是在每一份待扫描代码的根目录下自动生成脚本执行扫描任务,假设这个脚本为 scan.js,其内容如下:
// scan.js
const run = require('bcode');
process.on('message', async ({params}) => {
const scanMark = await run(JSON.parse(params));
process.send(scanMark);
});
因此这个脚本会在 A 扫描前生成在 /mnt/code/scan.js。
接下来对这个任务进行扫描:
const { fork } = require('child_process');
const p = fork('/mnt/code/scan.js', {
cwd: '/mnt/code',
});
p.send({
// ...
});
这种做法有两个问题,然而 bcode 在线上跑了半年多了我至今都没有意识到。
第一个问题是,如果我们的服务端代码部署的目录和扫描代码存放的在同一个目录,这样的方式没有问题,因为我们的服务依赖于 bcode,所以我们肯定会安装 bcode 这个包,因此 A 项目中自动生成的 scan.js 向上查找最终是可以从我们服务端代码的 node_modules 中找到这个包的。如下所示:
- server_code
- node_modules
- clone_projects
- A
- scan.js
但是有一天我们调整了目录,将这些待扫描的项目代码放到另一个磁盘呢?因为待分析的代码只是静态代码本身,而不需要运行,自然不会安装依赖,因此这种场景下扫描,那自然 scan.js 执行时就会由于找不到包而报错。
第二个问题是有必要对每个待扫描项目都生成 scan.js 吗?再次回头看我们开启子进程执行扫描的这段代码:
const p = fork('/mnt/code/scan.js', {
cwd: '/mnt/code',
});
真正需要关注的其实并不是脚本在哪里,而是我们的脚本工作在哪里。因为对于每一个任务,我们生成脚本的内容是一样的,只是脚本的参数不一样,而参数是在业务代码里处理的。也就是说我们只需要将 scan.js 放在业务代码里即可,而 cwd 参数就是每个被扫描项目的目录,这个才是动态变化的。
Session 保活机制
在每次分析完成后,需要在当前合并请求下方以 Review 的形式提一个问题,问题内容则是分析结果。GitLab 并没有对这个功能提供接口,因此需要自己抓包。研究了许久后,终于兜兜转转调了几个接口拿到参数实现了该功能,但有个很关键的问题,接口需要传递 Session。由于我们的 GitLab 登录实际上并不是走的它平台本身的登录,而是走的公司内部统一的登录,因此通过 private token 获取到的 Session 并不能用。最终没办法,只能自己手动去维护这个 Session。
策略很简单:
- 定时任务,每五分钟一次去访问 GitLab 首页
- 访问首页获得的响应内容为 html 文本,解析这段 html 判断是登录状态还是非登录状态
- 通知告警机制,一旦 Session 失效,及时通过内部通讯工具告知我
- 页面表单填写新的 Session 上报,服务端写入文件
第二点比较有意思,以前写爬虫的时候就处理过这种问题,在 Node 中可以使用 cheerio 这个包来解析 html。这里我是通过某个只有登录状态下才有的 class 来判断是否是登录状态,并不太靠谱,万一哪天改名了呢,但好像也没有更好的方式了。
突然想到我好像没有介绍过为什么叫 coderfly。我取名的时候在想,我这个工具是检测代码改动影响的,代码是程序员写的,我们的每一行改动有可能对其他功能造成影响,让我想起蝴蝶效应。因此我就将 coder 和 butterfly 组合到一起,叫它 coderfly。
这个项目给的时间并不多,节奏比较紧张,实际还有一些文章没有描述的细碎且棘手的问题和场景。我写得很开心,去年写 bcode 时也有这样的感觉,骑着电动车吹着风下班回家感觉今天很有意义和收获的满足感。我感觉我很适合做这种类型的工作,我不知道这种类型的工作有没有一种岗位,比如说开发者工具研发?测试(质量)工具开发?