开发代码质量检测工具,来给代码打打分
2021-06-25
TL;DR
最近这一个多月,我和组长一起做了一个代码质量检测工具,我们把它叫做质量模型,取名叫 bcode。
工具对外是一个 npm 包,安装后在项目目录下执行 bcode check [文件夹],便会扫描代码并上传报告,可打开命令行中输出的链接指向的页面获得代码分数和报告。
当前这个工具经过足够的测试,即将对内推出1.0版本提供使用。未来计划当我们所有规划的 feature 完成后,对外开源。
本文主要内容只涉及命令行部分。
代码扫描的维度
bcode 会从以下几个维度来检测代码:
- 代码重复度。即复制粘贴的代码比例
- 代码拼写检查。即将代码中拼写有误的单词都找出来
- 代码可维护性。即一个代码好不好维护,复杂度高不高
- 代码安全性。这个安全性非狭义的安全漏洞,且包括譬如"输入密码栏必须使用type=password,保证密码用掩码方式显示"等
- 最佳实践。即内置一些最佳实践,扫描后提示开发人员哪些地方有更好的做法或库有更好的替代品推荐等
整体架构
从整体来看,整个质量模型当前由三部分组成:
bcode-cli负责扫描代码,生成报告数据上报给bcode-serverbcode-server负责处理上报数据,根据模型计算出得分并存储到数据库。同时对bcode-client提供 API 接口bcode-client是一个对所有报告展示的网页,点击每个报告后可查看报告详情;同时还可以执行将认为误报的单词进行上报等操作
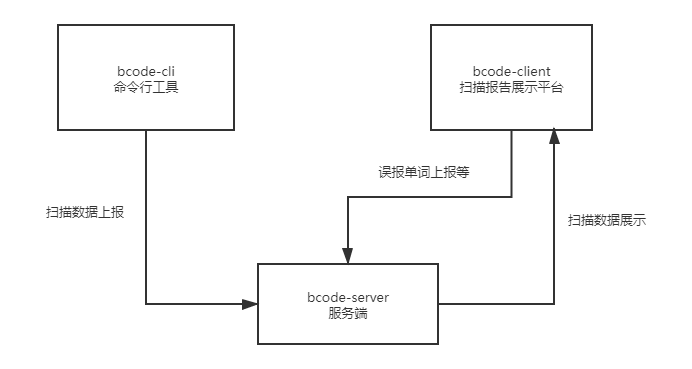
我主要负责 bcode-cli 和 bcode-server 的开发。cli 使用 TypeScript 和 Node.js 开发;server 使用 Nest.js 和 MongoDB 开发。
cli 部分
整体架构
cli部分整体架构如下:
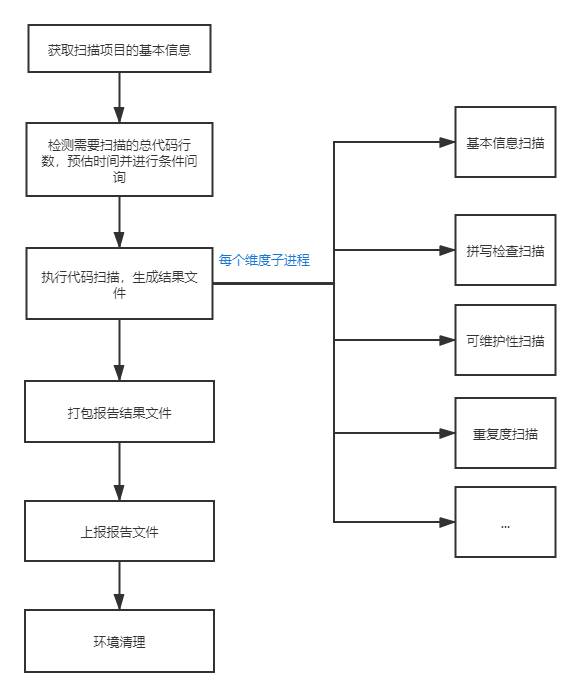
基本信息获取
基本信息主要是获取如下信息:
- 项目被扫描目录路径
- 项目的 git 仓库地址。这个通过分析 .git 文件即可
- 扫描的路径下,以数组形式保存过滤掉需要忽略的文件后需要扫描的文件,同时在此处可以计算得到所有文件的代码量总和
条件问询
在分析完成基本信息后,可以根据具体的需求来进行一些校验性质的工作。比如缺少了一些基本信息则不继续进行检查;比如在当前检测的总代码行数下,某些维度耗时较长,因此可以交互式命令行(Y/n)询问是否进行这个维度的检查。
扫描
每一个扫描任务,都是新开一个子进程来执行。
import * as path from 'path';
import { fork } from 'child_process';
mutiProcessScan();
async function mutiProcessScan (files) {
// 定义任务,每一个进程
const task = {
spellCheck: path.resolve(__dirname, './spell/fork.ts'),
copyCheck: path.resolve(__dirname, './copy/fork.ts'),
// ...
};
// 执行扫描任务
await processScan(task.spell, files);
await processScan(task.copyCheck, files);
// ...
}
async function processScan (taskFile, files) {
return new Promise((resolve, reject) => {
const p = fork(taskFile);
p.send({
files,
// ...其他一些需要传给每个任务的参数
});
p.on('close', () => {
// ...
});
p.on('exit', () => {
resolve();
});
p.on('error', () => {
reject();
});
})
}
有了上面这段代码封装,对于某一个维度我们只需要对外提供 fork.ts 即可。以拼写检查扫描为例:我们创建两个文件, /spell/fork.ts 和 /spell/index.ts。
// fork.ts
import { run } from './index.ts';
process.on('message', async ({ files }) => {
await run(files);
process.exit(1);
})
// index.ts
export const run = (files) => {
// 每一个维度检查要做的事情
// 做完后输出报告到指定目录
}
因此可以看出,如果要新增一个维度是很简单的。
拼写检查
拼写检查最开始实现时,想到的是 vscode 有个 code spell checker 插件,同时它是开源的,于是我计划参照它的源码来做。当我 clone 下代码时,我想如果是我,我会把核心的词库和检查部分等拆分出来单独作为一个包,于是我发现作者果然也是这么做的。核心的检查部分,作者抽成了cspell库。但是 cspell 本身就是一个命令行工具,而我要做的是一个脚本,我该如何将其为我所用?哈哈,我本身就是命令行工具的开发者,这个对我来说很简单,因为命令行工具的本质只是对外提供交互式接口,根据收到的对外指令,执行对应的函数而已。因此我只要使用 cspell 命令行处理所调用的核心函数即可。整个思路如下:
// index.ts
import {startSpellCheck} from './index.ts';
const run = async (files) => {
// 从 bcode-server 获取单词词库白名单,这些单词默认是正确的
// 单词结果生成文件 cspell.json
const cSpellPath = await handleSpellWords();
await startSpellCheck(files, {
config: cSpellPath
});
};
// check.ts
import App = require('cspell/dist/application');
import * as path from 'path';
const defaultOptions = {
issues: true,
config: path.resolve(__dirname, 'cspell.json') // 单词词库
// ...其他 cspell 配置
};
const genIssueEmitter = (issue) => {
// 将cspell检查到的错误单词写入到拼写检查报告文件中
};
const startSpellCheck = async (files, options={}) => {
const mergeOptions = Object.assign(defaultOptions, options);
// cspell库抛出的事件响应
// key 为事件名称,value 为回调函数
const emitter = {
issue: genIssueEmitter,
error: nullEmitter,
info: ...
};
return await App.lint(files, mergeOptions, emitter);
};
注意到在每次扫描拼写检查之前,会先从 bcode-server 获取当前项目的项目词库以及整个平台的平台此库,以在后面扫描时提供白名单,进一步提高扫描的准确率。
可维护性检查
代码的可维护性如何衡量?我最开始还很纳闷,这个应该是一个很感性的东西,还能被计算出来?其实有许多的论文都在研究这个。可以阅读这个分享进行了解,看看下面的引用文章。
从工程上来做,这方面的库很少,我们使用的是 typhonjs-escomplex。很简单的使用它就可以获得分析报告:
import escomplex from 'typhonjs-escomplex';
let source = 'let a = 1; ...';
escomplex.analyzeModule(source, {
// 配置项
});
不过这个库已经三年没有维护了,我最开始觉得这个库所在领域场景实在是太狭窄了,用户肯定不多,这个从 star 数也看得出来。star 数可能也会让作者感受到的外在正反馈比较少。后面和作者交流后,还有一个原因是作者转去别的兴趣领域了。
同时这个库不支持 Vue 文件,因此我给这个项目提了一个 PR ,没想到很快就收到了作者的答复。最后和作者交谈后,完全理解他的想法,因此我最终通过修改其代码作为一个单独的包来解决 Vue 项目扫描问题,同时兼容使用 Typescript 所编写的 Vue 项目。
import escomplex from 'typhonjs-escomplex';
const sources = '<template><div>test for vue</div></template> <script lang="javascript">@Component export default class Test {readonly test = 1;}</script>';
escomplex.analyzeModule(source, {
extName: 'vue',
commonjs: true,
logicalor: true,
newmi: true,
}, undefined, {
decoratorsBeforeExport: true, // 支持装饰器,且装饰器书写在 export 之前
decoratorsLegacy: true
});
重复度检查
重复度检查已有库做了这个事情,具体可以看看 jscpd。
数据上报
每一个维度的扫描都会生成一个 xxx.json 文件,最终将其打包成压缩包发送给 bcode-server 即可。
import * as fs from 'fs';
import * as tar from 'tar';
import * as path from 'path';
import FormData from 'form-data';
import axios from 'axios';
function packageFile () {
// 获取扫描报告文件的文件夹
const tmpDir = getTempDir();
const tgzFilename = path.resolve(path.dirname(tmpDir), 'report.tgz');
tar.create({
gzip: true,
cwd: tmpDir,
file: tgzFilename,
sync: true,
}, [...fs.readdirSync(tmpDir)]);
}
function report (tgzFilename) {
const formData = new FormData();
formData.append('file', fs.readFileSync(tgzFilename), tgzFilename);
return axios({
url: 'url',
method: 'POST',
headers: {
...formData.getHeaders()
},
data: formData
});
}
cli 部分目前的基本功能已完成,后期还有一些事情要做。当项目基本功能开发完成,我觉得其实从实现上来说,核心扫描部分每一个维度的扫描基本已经有现成的库,bcode-cli 要做的只是在工程上将整个扫描任务连起来达成自己的需求。这里面涉及到的每一个库都是值得花时间学习的,不过这些库都有很多可以优化的地方,比如说效率,希望日后我能给这几个库提提 PR。同时在开发过程中我还是收获到了一些经验,其中最重要的是如何增强工具的可调式性,毕竟我们推出的工具最后要是在使用者那里出 Bug 了要可以快速定位到 Bug 所在,以后我在这方面积累了更多经验,看能否写点什么分享出来。