开发了设计稿规范检视工具
2023-12-26
背景
规范的设计稿对 D2C(设计稿生成代码)是非常重要的,如果存在许多层级错乱的节点、冗余的节点、交叉的节点,那么势必在 D2C 开发的过程中需要处理许多的异常节点的处理和计算,有很多异常场景很难通过代码的手段去解决,从而很难生成正确的高可用性的前端代码。因此 D2C 的实践过程中需要提炼出许多 D2C 的设计规范让设计师配合。
同时,设计团队也有自己的设计规范,在设计师的日常设计中需要进行设计检视,类似于我们开发人员的 code review。间距、颜色等一一核对的检视是枯燥的。
如果有个工具可以让设计师在设计自检或设计评审时一键检视存在的设计问题,那么无论对于设计稿的质量或者是设计效率都有很大的帮助。设计稿检视工具的需求应运而生。它就像是设计稿的 ESLint。
很显然,由于两种不同角色对规范的不同要求,因此设计稿检视工具的规则会分为 D2C 规则和设计规则两种类型。
整体效果
选中设计稿,使用设计稿检视插件一键检测
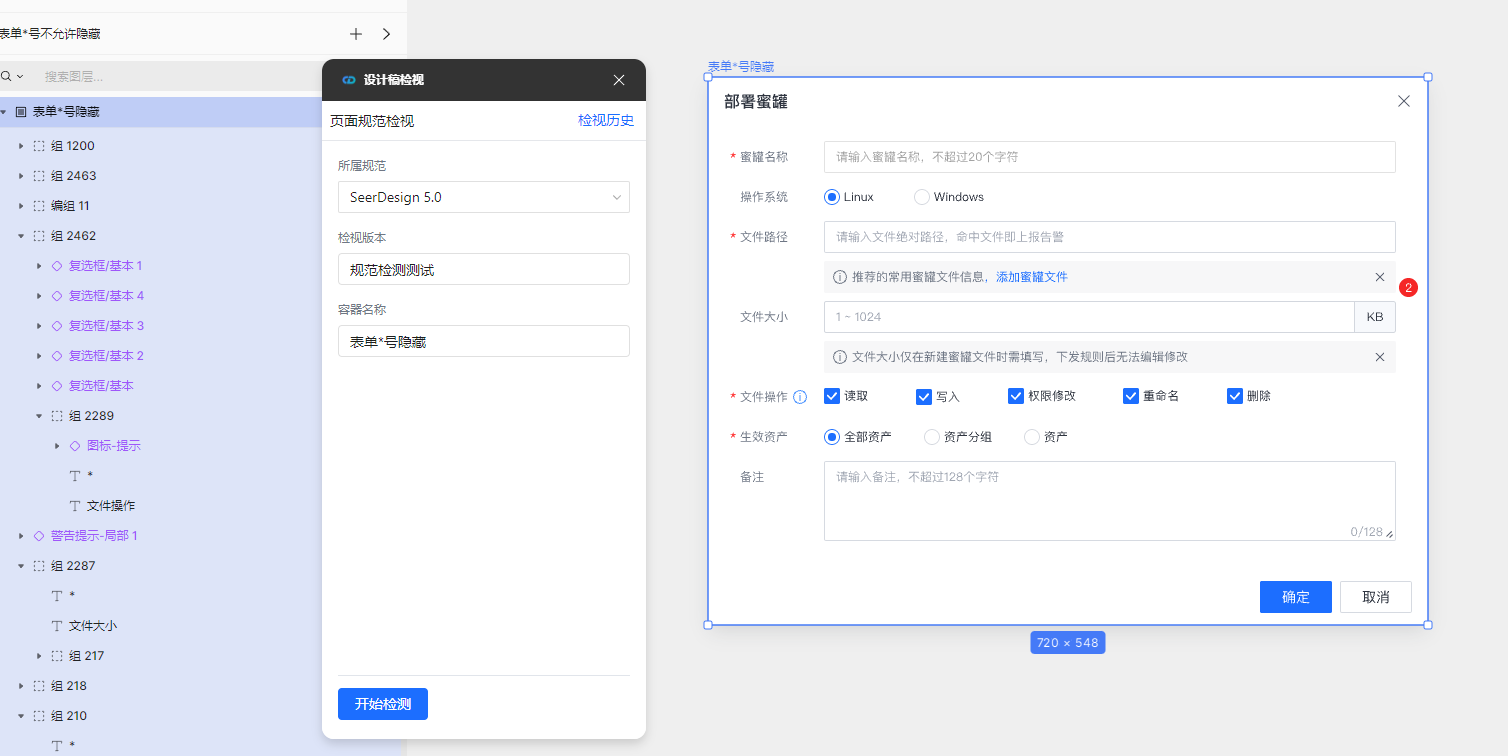
检测完成自动打开检测报告
检测报告以画板的形式展示(和设计软件一致的操作方式),在这里可以进行问题查看、问题忽略、问题过滤等操作,同一个设计稿被忽略的问题在下一次检视时将不会提示:
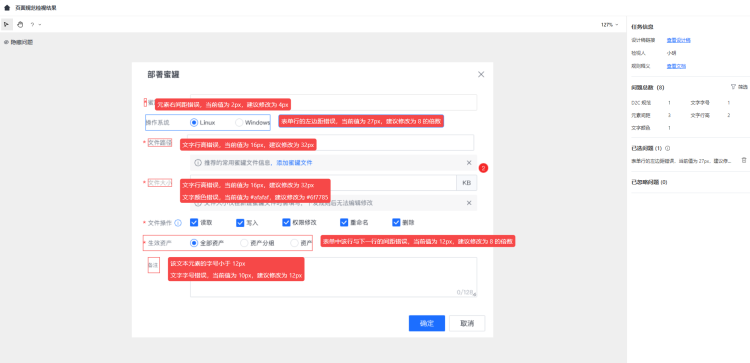
历史记录和数据汇总
所有的检视记录会按照「同一个版本」,「同一个设计稿」的维度进行聚合,同时会对这些记录进行数据分析和汇总:
实现:整体流程
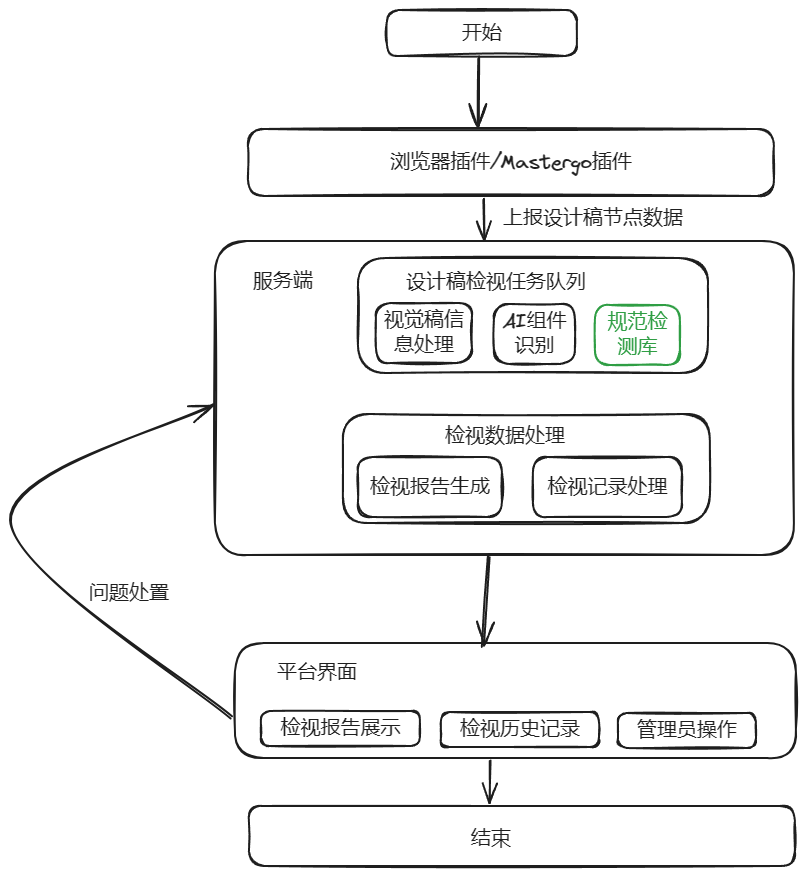
插件端
用户在 Mastergo 设计稿页面上选中需要检视的设计稿后点击插件开始检测,插件会对设计稿进行节点提取(节点树)、图片导出等设计稿数据处理,将数据发送给服务端
服务端
服务端收到检视任务后,主要做几件事:
- 对上报的设计稿数据做进一步必要的处理,比如将插件上报的图片 (base 64)转为静态资源存储,用于 AI 识别
- 将检视任务加入任务队列中,在任务队列中会对设计稿进行 AI 组件识别,得到组件识别结果。将这个和原始设计稿信息一起提供给「规范检测库」进行检视,获得检视结果
- 搜索相同的设计稿的历史记录,将这个设计稿以前处置(如某个问题被忽略)延续到本次检视操作;同时将相同的设计稿的检视结果进行合并
组件识别结果:
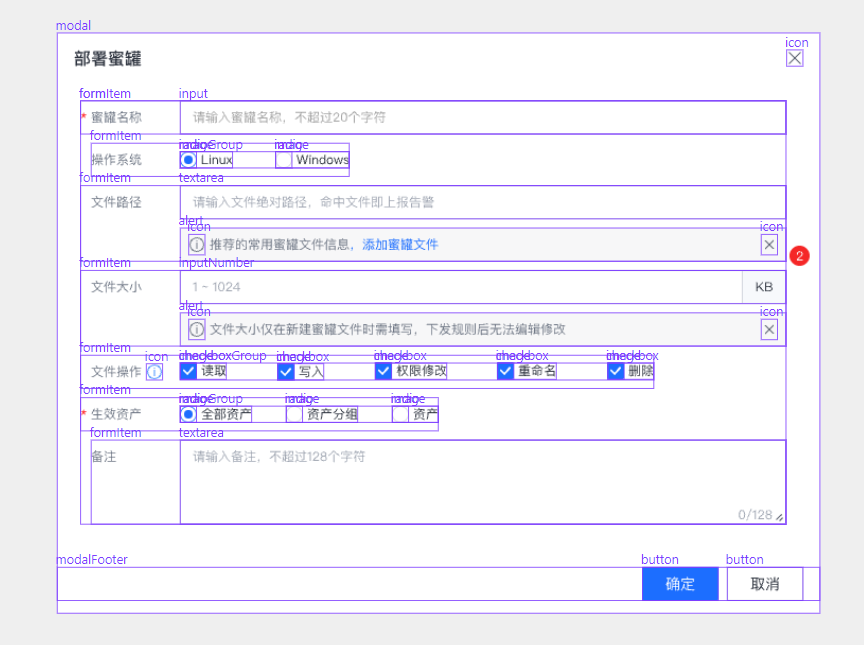
UI 平台
提供报告展示、问题处置、历史记录、管理员操作等功能。
整体流程就是普通的 web 开发,毫无疑问最核心的功能和能力在于「规范检测库」。
实现:规范检测库
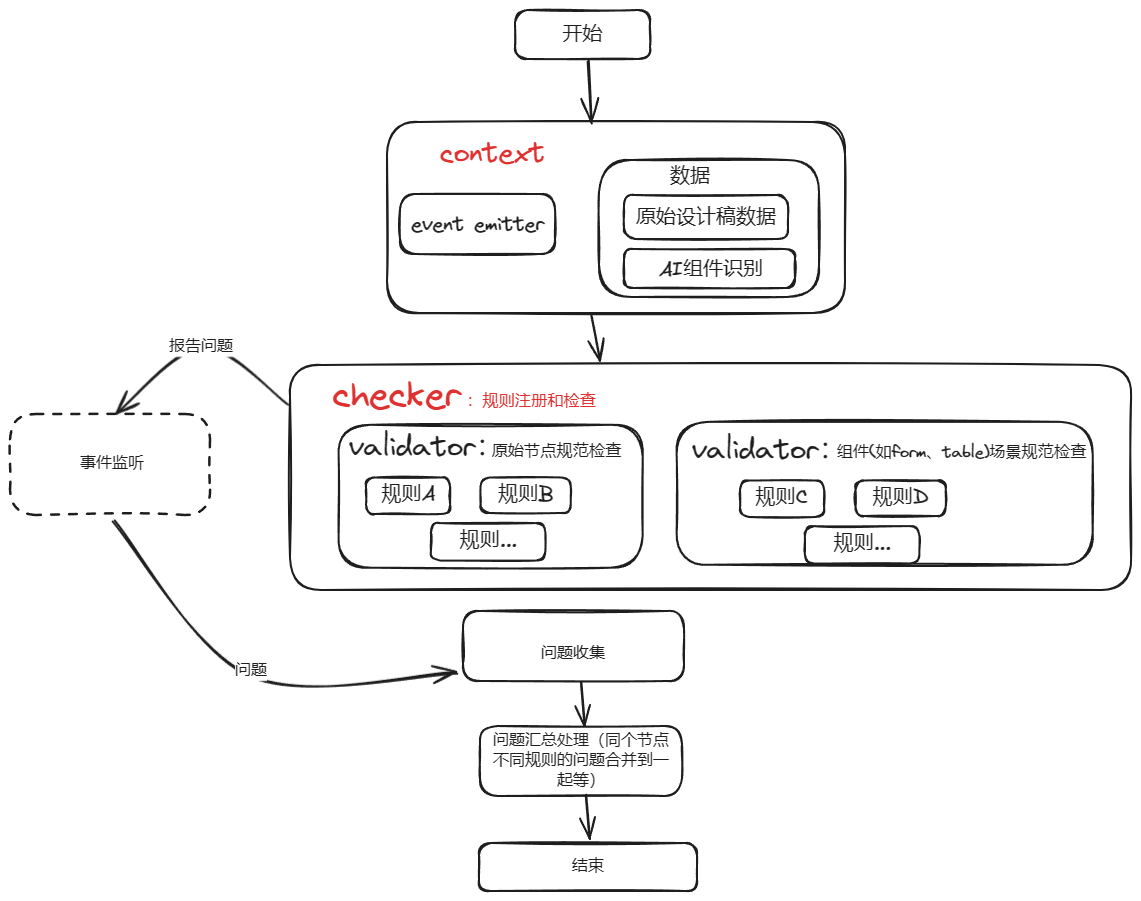
输入数据
我们需要检测的对象按照场景划分为两种:设计稿原始节点类型和具体的场景组件。
设计稿原始节点类型
比如校验「TEXT 节点」的最小字号、「TEXT 节点」之间不能存在交叉、「子节点」大小不能超过「父容器」的大小。
具体的场景组件
表单、表格等具体场景我们是无法从设计稿原始节点中判断出来的,这也是服务端为什么对设计稿进行 AI 组件识别的原因。通过 AI 识别我们知道具体的(场景)组件的位置、大小。
因此「规范检测库」的输入就是设计稿的原始节点(树)和设计稿组件识别结果。
上下文环境
有些规则需要计算节点之间的关联关系,因此单个规则的输入不仅仅是当前节点。我们可以抽象一个 context 注入到每个规则中去,校验过程中所有规则共享。这种 context 的思想在各种库中非常常见。
校验过程中需要不断地收集每个规则的校验结果,我们可以在 context 中增加一个 event emitter,规则将问题”广播出去“,然后统一由一个收集者负责接收广播,收集问题。
策略模式
如果我们制定了文本规范,那么则会对文本节点进行对应的规则检视。方式则是对输入的数据进行遍历,遇到类型为 TEXT 的节点则进行规则检视;对于表单规范也是同理。用伪代码表示这个过程:
traveAndValidate (tree, node => {
if (node.type === 'TEXT') {
checkRule1();
checkRule2();
}
if (node.type === 'xxxx') { // ...}
// ...
});
这样的方式显然是不行的,if-else 多、规则可维护性差、复用性差。这样的场景其实在表单的校验中也很常见,不同的表单有不同的校验规则。对于这种问题策略模式就要派上用场了,下面是使用策略模式制定一个校验器。
// 一条规则的定义
interface Rule {
name: string; // 规则名
description: string; // 规则描述
level: 'warn' | 'error' | 'info'; // 报错级别
category: ' D2C' | 'design'; // 类别
checker: Function; // 规则实现
}
class ComponentValidator {
checkerMap: {[nodeType: string]: string[]} = {}; // 每个组件绑定的规则
strategies: Record<string, Rule>; // 策略
constructor (strategies: Record<string, SubRule>) {
this.strategies = strategies;
}
// 注册不同类型组件的校验规则
add (component: string, rules: string[]) {
this.checkerMap[component] = rules;
}
// 遍历节点树,对节点进行规则检查
traveAndValidate (tree: Tree<Node>, context: LintContext) {
const component = tree.component;
if (this.checkerMap[component]) {
for (let componentRule of (this.checkerMap[component] || [])) {
this.strategies[componentRule].checker(tree, context);
}
}
for (const childComponent of (tree.children || [])) {
this.traveAndValidate(childComponent, context);
}
}
start (context: LintContext) {
this.traveAndValidate(context.componentTree, context);
}
}
当有了这个校验器后,我们就可以很方便的维护规则了。只需要关注规则的逻辑实现,如果某个组件需要使用某条规则,只需要它需要绑定的规则数组里增加规则名称即可。
// 先制定规则,以及将组件和对应的规则进行映射
const rules = {
ruleA: {
name: 'ruleA',
description: 'ruleA description',
level: 'warn',
category: 'design',
checker (node, context) { // do something }
},
};
const registerMap = {
form: ['ruleA', 'ruleB'],
table: ['ruleC'],
select: ['ruleD']
};
// 检查所有组件是否符合规范
function componentChecker (context: LintContext) {
const validator = new ComponentValidator(rules);
Object.entries(registerMap).forEach(([type, rule]) => {
validator.add(type, rule);
});
validator.start(context);
}
规范实现
规范实现本质上就是按照规则要求进行各种节点之间的关联计算或者是节点的属性检查,在上面 Rule 的定义中可以看到它本质上就是 checker 函数的实现。因为最终问题都是在规则内部使用事件广播的方式由问题收集器统一收集处理,所以对于每个规则内部的实现可自由发挥,只需要最终报告的问题结果的数据结构保持统一。
规范检测工具的核心在规范检测库,而规范检测库的核心在规范实现。有些规范的实现一点也不简单。比如对于表单,要检查 label 之间是否左对齐、要检查表单的单个一行的各个元素之间的间距,需要提取所有的 label 成组,单行成组等等,要把表单不断地横着分割,竖着切割。横看成岭侧成峰,远近高低各不同。
此外,这些规则形成的规则库是以插件的形式在「规范检测库」加载的,所以后续不同的设计规范只需关注规则的具体实现即可。
其他
本节为工具的开发或者落地过程中的一些零碎的问题。
和设计师沟通
由于使用者是设计师,所以实现工具的过程中需要和设计师进行大量的沟通工作。包括:
- 工具的交互实现
- 设计规范的提取
- 工具的宣贯和推广
因此需要在设计团队找到一个设计负责人来负责工具的工作。工具的交互实现倒是和平时开发业务差不多,但规范的提取就不那么容易了。因为设计规范虽然看起来是有明文的条条框框的,但是很零碎,要转为工具实现的代码逻辑还有很多的精简、规则定义、报错文案等工作。
同一个设计稿如何判断
无论是下面涉及的「问题忽略」功能,还是「同个设计稿的记录合并」等,都需要能够判断两张设计稿是不是同一个设计稿。
一个设计稿有两种可能:
- 整个设计稿中各个节点编组为一个组合
- 设计稿未被编组,是零碎的节点
第一种场景下,插件上报的设计稿信息中有唯一的 id,所以在 server 我们可以通过这个 id 进行查询即可找到相同设计稿的历史检视记录。
第二种场景下,没有唯一的 id 存在,那么如何判断设计稿是同一张呢?经过思考,这种情况下一张设计稿本质上是由大量的节点(每个节点有唯一 id)组成的,所以判断是否是同一个设计稿只能通过这个数组来判断,所以我们通过节点 id 数组的相似度(交并比)来判断是否是同一张设计稿。
/**
* 使用数组的交并比来判断相似度
* @param ids 当前被对比的设计稿节点的id
* @param standardIds 对比的基准
*/
export const isSameDraftByNodeSimilarity= (ids: string[], standardIds: string[]) => {
const iouThread = 0.9;
const intersection = ids.filter(id => standardIds.includes(id));
const union = new Set([...ids, ...standardIds]);
if (union.size === 0) return false;
const iou = (intersection.length) / union.size;
return iou > iouThread;
};
如果这两种情况下都没有找到相同的设计稿,那么就认定为新设计稿。很显然这种策略从逻辑上来看存在一些的问题。举个例子,一个设计稿还未完成时(少量节点)检视和最终完成时检视由于节点的增删可能就会被判断为不同设计稿。不过从现实使用工具的时间来看(最终设计完成准备评审),这个策略是满足要求的。
忽略问题的实现
规则的实现存在 bug 或者 AI 识别存在不准等都可能导致检查出现误报,因此在报告展示界面提供了「问题忽略」操作,本次设计稿检视忽略的问题在下一次检视时将不再提示。
每一个被报告的问题都会生成一个「问题id」,所以问题忽略就是将被忽略的「问题id」从结果中过滤即可。由于同一个设计稿的判断的问题解决了,那么只要保证同一个节点的同一个问题的「问题id」每次检视都是唯一的即可。那么这个「问题id」的生成是否可以使用[节点 id]-[问题类型]-[问题报错文本]呢?
理论上同一个节点在每次检查时这些值确实应该是不变的,但是在我的场景中存在一点问题:同一个节点的 id 不一定保持不变。在设计稿中,每个节点都有一个唯一 id,所以设计稿节点中的节点 id 是不变的。但是 AI 识别组件时,每次生成的组件节点都会生成一个不同的 id,所以这导致同一个设计稿在每次 AI 识别时,同一个组件的 id 是不一致的。所以对于组件,必须想一个不变量来替换「节点id」,我选择使用 x-y-width-height 来替代「节点id」,因为理论上只要 AI 识别稳定,同一个设计稿每次同一个区域的识别结果应当是一致的。
最终使用md5对这些信息进行编码,从而达到同一个节点的同一个问题每次检视都是相同的 id 的目的。
function genIssueId (
node: NodeInfo,
category: keyof typeof IssueCategory,
msg: string,
) {
const {x, y, width, height} = node;
let nodeMark = node.id;
let issueInfo = `${category}-${msg}`;
// 因为这两种节点每次的id并不是固定的,所以用区域来标识节点
// 会存在误判,不过可以接受,因为区域变化说明设计稿有改动,那这一块的校验内容也要变化,可以理解为产生了新的问题
if (/@AI/.test(node.id)) {
nodeMark = `${x}-${y}-${width}-${height}`;
}
return md5(`${nodeMark}-${issueInfo}`);
}
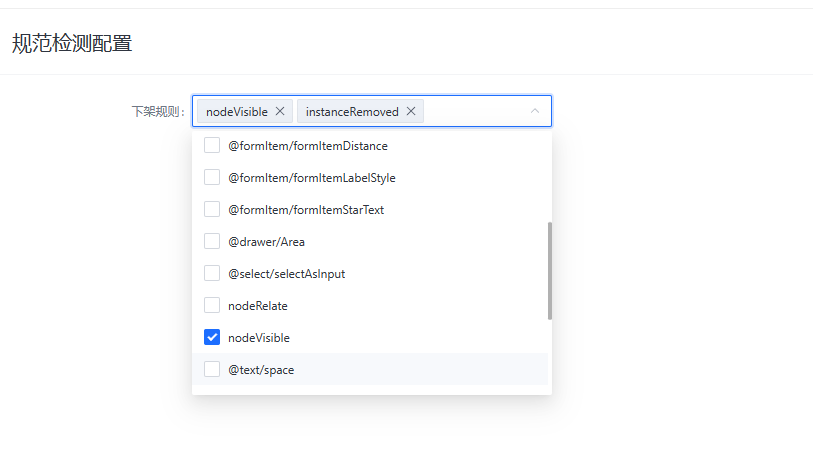
规则下架
如果某个规则上线后有严重的问题,可能导致每次检视都有很多误报,所以需要有个规则下架的机制。这个实现也很简单:
- 「规范检测库」对外提供接口获取所有规则名,管理员可以对这些规则进行下架操作
- 任务队列中执行规范检测时,获取被下架的规则传入「规范检测库」,在注册规则之前将这些下架规则忽略即可。
碎语
这个工具包含了插件开发、服务端开发、规范检测库的实现、UI 平台开发,一个人独立开发了两个月时间,工作量大时间紧。我将它拆分为三个迭代,每个拆分的小迭代都顺利的按时完成。经过演示、内测、宣贯,设计团队在这个月开始使用了。和高频使用的设计师进行沟通时,得到的都是提质提效的肯定反馈,还是很欣慰的。